deckformat: Reading and conversion of input decks¶
Functionality for reading, writing, and processing ECLIPSE input files. The core module offers simple functionality for reading a selection of keywords that mostly describe grids and cell-based properties. The deckreader module reads a larger portion of complete input files, which generally contain the following sections:
- RUNSPEC: specification of the run, including grid size, phases, table size, etc
- GRID: grid geometry and topology and petrophysics (porosity, permeability, net-to-gross)
- EDIT: user-defined changes to the grid data after they have been processes
- PROPS: fluid and rock properties (relative permeability, PVT, etc)
- REGIONS: user-defined regions with different relative permeability and capillary curves, etc
- SOLUTION: description of how to initialize the model
- SUMMARY: defines what kind of data to output
- SCHEDULE: definition of wells and description of operating schedule
Along with the input reading, the module offers several functions to construct fundamental MRST objects (e.g., grids, fluids, rock-properties or wells) from the descriptions of a particular simulation deck.
This module also supports reading and processing ECLIPSE output files (such as grid, init, summary and restart vectors). This enables visualising an ECLIPSE simulation case with associate dynamic data in MRST as well as using existing ECLIPSE runs to initialise an MRST simulation case.
-
Contents¶ ECLIPSE Support for reading/writing ECLIPSE input/output mapAxes - Transform lateral position from map to local coordinate system
-
mapAxes(pos, MA)¶ Transform lateral position from map to local coordinate system
Synopsis:
p = mapAxis(pos, ma)
Parameters: - pos – nx2 vector of map coordinates that are to be transformed
- ma – 6x1 vector of points: x1 y1 x2 y2 x3 y3 Here: (x1,y1) describes a point on the y-axis, (x2,y2) is the grid origin, and (x3,y3) is a point on the x-axis
Returns: p – nx2 vector of coordinates transformed to local coordinate system
Example:
p = mapAxes([x y], [100 100 0 100 100 0])
-
Contents¶ DECKINPUT
- Files
- applyOperator - Apply ECLIPSE/FrontSim operator to input array. boxKeyword - Uniform handling of BOX keyword convertDeckUnits - Convert ECLIPSE/FrontSim input deck units to MRST conventions endboxKeyword - Uniform handling of ENDBOX keyword initializeDeck - Initialise simple structure of ECLIPSE format type matchWells - Match wells to keyword records readDefaultedKW - Read data, possibly containing default designators, for a single keyword. readDefaultedRecord - Read data, possibly containing default designators, for a single record. readEclipseDeck - Read Simplified ECLIPSE input deck. readEDIT - Read edit readGRID - deck = readGRID(fid, dirname, deck) readGridBoxArray - Input grid array (global cell based) corresponding to current input box readImmisciblePVTTable - Input immiscible ECLIPSE/FrontSim PVT table (e.g., PVDO, PVDG). readMisciblePVTTable - Input miscible ECLIPSE/FrontSim PVT table (e.g., PVTO, PVTG). readPROPS - deck = readPROPS(fid, dirname, deck) readREGIONS - Read regions readRelPermTable - Input ECLIPSE/FrontSim saturation function table (SWOF/SGOF &c). readRUNSPEC - Read runspec readSCHEDULE - Read schedule readSOLUTION - Read solution readSUMMARY - Read summary readVFPINJ - Read VFP tables for injector readVFPPROD - Read VFP tables for producer readWellKW - Read well definitions from an ECLIPSE Deck specification. replaceKeywords - Replace keywords. Internal function
-
applyOperator(sect, fid, kw)¶ Apply ECLIPSE/FrontSim operator to input array.
Synopsis:
sect = applyOperator(sect, fid, kw)
Parameters: - sect – Structure array representing the current deck section.
- fid – Valid file identifier (as obtained using FOPEN) to file containing array operator description. FTELL(fid) is assumed to be at the start of the description (i.e., after the keyword which prompted the reading of this table).
- kw – Operator keyword. Must be one of ADD – Add constant value to existing array. COPY – Copy values from existing array to other array. EQUALS – Assign constant value to array. MAXVALUE – Array elements must not exceed specific value. MINVALUE – Array elements must not be less than given value. MULTIPLY – Multiply existing array by constant value.
Note
Box limits for the operator ‘kw’ are managed independently from the limits that affect the property keywords (e.g., PERMX). The limits are initialised to that of the most recent input box defined by the BOX or ENDBOX keywords–or the entire model if no such box limits have been previously selected in the input deck.
Returns: sect – Updated deck section structure array. See also
-
boxKeyword(fid)¶ Uniform handling of BOX keyword
Synopsis:
boxKeyword(fid)
Parameters: fid – Input stream (as defined by FOPEN) from which to retrieve the next input box definition. Returns: Nothing, but resets the global input box depending on keyword data. See also
private/gridBox.
-
convertDeckUnits(deck, varargin)¶ Convert ECLIPSE/FrontSim input deck units to MRST conventions
Synopsis:
deck = convertDeckUnits(deck) deck = convertDeckUnits(deck, 'pn1', pv1, ...)
Parameters: - deck – An ECLIPSE/FrontSim input deck as defined by function ‘readEclipseDeck’.
- 'pn'/pv –
A list of ‘key’/value pairs defining optional parameters. The supported options are:
- verbose – Whether or not to emit informational messages
- if a section is skipped. Logical. Default value: verbose = mrstVerbose
Returns: deck – An ECLIPSE/FrontSim deck where all quantities affected by varying units of measurements have been converted to MRST’s strict, SI only, conventions.
See also
-
endboxKeyword()¶ Uniform handling of ENDBOX keyword
Synopsis:
endboxKeywordParameters: None. – Returns: Nothing, but resets the global input box to encompass entire model. See also
private/gridBox.
-
initializeDeck()¶ Initialise simple structure of ECLIPSE format type
Synopsis:
deck = initializeDeck()
- RETURNS
- deck - Output structure containing the known, which is empty,
This structure contains the following fields, corresponding to separate deck sections documented in the ECLIPSE or FrontSim manuals:
RUNSPEC - Basic meta data (dimensions &c). GRID - Grid specification (e.g., COORD/ZCORN and PERMX) PROPS - Fluid properties (e.g., PVT and relperm). REGIONS - Region partition. May be empty. SOLUTION - Initial conditions. SCHEDULE - Time step and well controls (&c).
See also
readEclipseDeck,convertDeckUnits,initEclipseGrid,initEclipseRock,initEclipseFluid.
-
matchWells(lookup, source)¶ Match wells to keyword records
Synopsis:
[input, pos, rec] = matchWells(lookup, source)
Parameters: - lookup – Cell array of strings defining what wells to look for. The strings must be either well names or well templates. Well lists are currently not supported.
- source – List of wells to match by name.
Returns: input – Array of numeric indicies into ‘lookup’ that specify which of the ‘lookup’ records where successfully matched. The unmatched lookups can be determined by code like
matched = false([numel(lookup), 1]); matched(input) = true; unmatched = find(~ matched);
pos – Indirection array into source record list. Size equal to (NUMEL(input) + 1)-by-1. Those ‘source’ records that are matched by lookup record ‘input(i)’ are found in positions
pos(i) : (pos(i + 1) - 1)
of the record list.
rec – Source record list. Array of numeric indices into ‘source’ that are matched by records in ‘lookup’.
Note
Well names and well template names are matched case insensitively.
-
readDefaultedKW(fid, template, varargin)¶ Read data, possibly containing default designators, for a single keyword.
Synopsis:
data = readDefaultedKW(fid, template) data = readDefaultedKW(fid, template, 'pn1', pv1, ...)
Parameters: - fid – Valid file identifier as obtained from FOPEN.
- template –
An n-element CELL array constituting a template for the next record. Assumed to contain ‘n’ copies of a default value. The typical default is the string ‘NaN’, but any value may be used as ‘readDefaultedRecord’ does not inspect this value in any way.
To conveniently generate an n-element CELL array, each element of which contains the string ‘NaN’, issue a statement of the form:
template(1 : n) = { ‘NaN’ } - 'pn'/pv –
List of ‘key’/value pairs defining optional parameters. The supported options are:
- NRec – Maximum number of records to input. Integer.
- Default value: Inf whence input will terminate upon detecting an empty input record (usually consisting only of a slash character).
Returns: data – Keyword data. An m-by-n CELL array, the rows of which corresponds to the individual records while the columns represent the individual fields. Default field values are derived from the input ‘template’.
Note
It is the caller’s responsibility to supply default values in the input ‘template’ which can be reliably distinguished from all (expected) data for any given keyword.
Data reading terminates when the input reader detects an empty record.
See also
-
readDefaultedRecord(fid, rec)¶ Read data, possibly containing default designators, for a single record.
Synopsis:
rec = readDefaultedRecord(fid, template)
- DESCRIPTIONS:
Reads a single record, containing a specific number of fields, whilst replacing input default value designators of the form ‘n*’ (where ‘n’ is an integer) with ‘n’ copies of a user-supplied default value.
Function ‘readDefaultedRecord’ supports early record termination (i.e., the terminator character ‘/’ occurring before all fields have been input) in which case any trailing fields will be assigned the default value supplied by the caller.
Parameters: - fid – Valid file identifier as obtained from FOPEN.
- template –
An n-element CELL array constituting a template for the next record. Assumed to contain ‘n’ copies of a default value. The typical default is the string ‘NaN’, but any value may be used as ‘readDefaultedRecord’ does not inspect this value in any way.
To conveniently generate an n-element CELL array, each element of which contains the string ‘NaN’, issue a statement of the form:
template(1 : n) = { ‘NaN’ }
Returns: rec – Fully, or partially, filled ‘template’ CELL array. Any non-defaulted input data will be entered, in STRING form, into the corresponding ‘rec’ element whilst leaving defaulted data in its input ‘template’ form.
Note
It is the caller’s responsibility to supply default values in the input ‘template’ which can be reliably distinguished from all (expected) data for any given keyword record. Moreover, an all-default return value (i.e., rec = template) typically constitutes the end of the keyword data.
See also
-
readEDIT(fid, dirname, deck)¶ Read edit
-
readEclipseDeck(fn, varargin)¶ Read Simplified ECLIPSE input deck.
Synopsis:
deck = readEclipseDeck(fn)
Parameters: fn – String holding name of (readable) input deck specification. Note: The specification is assumed to be a physical (seekable) file on disk, not to be read in through (e.g.) a POSIX pipe.
Returns: deck – Output structure containing the known, though mostly unprocessed, fields of the input deck specification. This structure contains the following fields, corresponding to separate deck sections documented in the ECLIPSE or FrontSim manuals:
RUNSPEC - Basic meta data (dimensions &c). GRID - Grid specification (e.g., COORD/ZCORN and PERMX) PROPS - Fluid properties (e.g., PVT and relperm). REGIONS - Region partition. May be empty. SOLUTION - Initial conditions. SCHEDULE - Time step and well controls (&c).
Note
This function does no error checking. There is an implicit assumption that the input deck is properly formed.
See also
convertDeckUnits,initEclipseGrid,initEclipseRock,initEclipseFluid.
-
readGRID(fid, dirname, deck)¶ deck = readGRID(fid, dirname, deck)
-
readGridBoxArray(sect, fid, kw, nc, dflt)¶ Input grid array (global cell based) corresponding to current input box
Synopsis:
section = readGridBoxArray(section, fid, kw, nc) section = readGridBoxArray(section, fid, kw, nc, dflt)
Parameters: - section – Deck section data structure. Expected to be one of GRID, PROPS, REGIONS, or (in the future) SCHEDULE.
- fid – Valid file identifier as defined by function FOPEN. The file ponter FTELL(fid) is expected to be positioned directly after the keyword that prompted reading of a grid array (e.g., directly after the PERMX keyword).
- kw – Particular keyword (string) to which the next input data will be assigned. Input data will be extracted from the ‘fid’ for all (global) cells corresponding to the current input box.
- nc – Number of cells in the global grid model. Corresponds to PROD(deck.RUNSPEC.DIMENS). This number is used for preallocating the output array (‘kw’) if it does not already exist in the input deck section represented by ‘section’.
- dflt – Value assigned to unspecified array elements. This number is used for preallocating the output array (‘kw’) if it does not already exist in the input deck section represented by ‘section’. Treated as zero if unspecified, meaning that the output array gets allocated and zero-initialized if this parameter is not specified at the call site.
Returns: section – Deck section data structure, modified such that new values are assigned to the array ‘fld’ in the cells corresponding to the current input box.
See also
readGRID,readREGIONS,private/boxIndices,private/gridBox.
-
readGridBoxArrayDP(sect, fid, kw, nc)¶ Input grid array (global cell based) corresponding to current input box
Synopsis:
section = readGridBoxArray(section, fid, kw, nc)
Parameters: - section – Deck section data structure. Expected to be one of GRID, PROPS, REGIONS, or (in the future) SCHEDULE.
- fid – Valid file identifier as defined by function FOPEN. The file ponter FTELL(fid) is expected to be positioned directly after the keyword that prompted reading of a grid array (e.g., directly after the PERMX keyword).
- kw – Particular keyword (string) to which the next input data will be assigned. Input data will be extracted from the ‘fid’ for all (global) cells corresponding to the current input box.
- nc – Number of cells in the global grid model. Corresponds to PROD(deck.RUNSPEC.DIMENS). This number is used for preallocating the output array (‘kw’) if it does not already exist in the input deck section represented by ‘section’.
Returns: section – Deck section data structure, modified such that new values are assigned to the array ‘fld’ in the cells corresponding to the current input box.
See also
readGRID, readREGIONS, private/boxIndices, private/gridBox.
-
readImmisciblePVTTable(fid, ntab, ncol)¶ Input immiscible ECLIPSE/FrontSim PVT table (e.g., PVDO, PVDG).
Synopsis:
Table = readImmisciblePVTTable(fid, ntab, ncol)
Parameters: - fid – Valid file identifier (as obtained using FOPEN) to file containing the PVT table. FTELL(fid) is assumed to be at the start of the PVT table (i.e., after the keyword, if any, which prompted the reading of this table).
- ntab – Number of PVT tables to input. Typically corresponds to the ECLIPSE/FrontSim parameter ‘NTPVT’ (item two of ‘TABDIMS’).
- ncol – Number of columns in each of the ‘ntab’ tables.
Returns: Table – An ntab-by-1 cell array of immiscible PVT tables. An immiscible PVT table is an m-by-ncol array of type DOUBLE. It is the caller’s responsibility to correctly interpret the individual columns of a specific table.
Note
Immiscible PVT tables in ECLIPSE or FrontSim contain an arbitrary number of records, each record separated by whitespace (typically newline, ‘n’). A table is terminated by a slash character (‘/’).
See also
-
readMisciblePVTTable(fid, ntab, ncol, kw)¶ Input miscible ECLIPSE/FrontSim PVT table (e.g., PVTO, PVTG).
Synopsis:
Table = readMisciblePVTTable(fid, ntab, ncol)
Parameters: - fid – Valid file identifier (as obtained from FOPEN) to file containing the PVT table. FTELL(fid) is assumed to be at the start of the PVT table (i.e., after the keyword, if any, which prompted the reading of this table).
- ntab – Number of PVT tables to input. Typically corresponds to the ECLIPSE/FrontSim parameter ‘NTPVT’ (item two of ‘TABDIMS’).
- ncol – Number of columns in each of the ‘ntab’ tables.
Returns: Table – An ntab-by-1 cell array of miscible PVT tables. A miscible PVT table is represented as a data structure (STRUCT) with the following fields:
- key – Primary lookup key for data table interpolation.
This is typically pressure or Rs values. The key may be used for binning input quantities before interpolating the ‘data’ portion related to each key. For binning purposes, ‘key’ should normally be sorted in the input source represented by ‘fid’.
- pos – Indirection map into ‘data’. Specifically, the
data related to ‘key(i)’ is found in the submatrix
data(pos(i) : pos(i + 1) - 1, :)
- data – Table data. An m-by-ncol array of type DOUBLE.
It is the caller’s responsibility to correctly interpret the individual columns of a specific table.
Note
Miscible PVT tables in ECLIPSE or FrontSim contain an arbitrary number of records, each record terminated by a slash character (‘/’). At least one record (the last), and optionally all other records, must specify additional data (typically Rv or pressure values for undersaturated fluid solutions).
Function ‘readMisciblePVTTable’ does not verify or enforce sorted keys.
The return value, ‘Table’, may be converted to a structure array using the statement:
Table = [ Table{:} ] .’ % or: Table = vertcat(Table{:})See also
-
readPROPS(fid, dirname, deck)¶ deck = readPROPS(fid, dirname, deck)
Otherwise intentionally undocumented.
-
readREGIONS(fid, dirname, deck)¶ Read regions
-
readRUNSPEC(fid, dirname, deck)¶ Read runspec
-
readRelPermTable(fid, kw, ntab, ncol)¶ Input ECLIPSE/FrontSim saturation function table (SWOF/SGOF &c).
Synopsis:
Table = readRelPermTable(fid, kw, ntab, ncol)
Parameters: - fid – Valid file identifier (as obtained using FOPEN) to file containing the rel-perm table. FTELL(fid) is assumed to be at the start of the rel-perm table (i.e., after the keyword, if any, which prompted the reading of this table).
- kw – Keyword that prompted this saturation function table read. Used in diagnostic messages only.
- ntab – Number of relative permeability tables to input. Typically corresponds to the ECLIPSE/FrontSim parameter ‘NTSFUN’.
- ncol – Number of columns in each of the ‘ntab’ tables.
Returns: Table – An ntab-by-1 cell array of relative permeability tables. Any default values in columns 2:ncol specified by the syntax ‘1*’ in the input data are replaced by linearly interpolated data from the non-default values in the corresponding column.
See also
swof,sgof,swfn,sgfn.
-
readSCHEDULE(fid, dirname, deck, varargin)¶ Read schedule
-
readSOLUTION(fid, dirname, deck)¶ Read solution
-
readSUMMARY(fid, dirname, deck)¶ Read summary
-
readVFPINJ(fid)¶ Read VFP tables for injector
-
readVFPPROD(fid)¶ Read VFP tables for producer
-
readWellKW(fid, w, kw)¶ Read well definitions from an ECLIPSE Deck specification.
Synopsis:
w = readWellKW(fid, w, kw)
Parameters: - fid – Valid file identifier as obtained from FOPEN.
- w – Structure array containing current well configuration. May be empty if the well keyword is ‘WELSPECS’.
- kw – Current well specification keyword.
Returns: w – Updated structure array containing new data for keyword ‘kw’.
- COMMENTS:
The currently recognized well keywords are:
‘WELSPECS’, ‘COMPDAT’, ‘WCONHIST’, ‘WCONINJ’, ‘WCONINJE’, ‘WCONINJH’, ‘WCONPROD’, ‘GRUPTREE’, ‘WGRUPCON’, ‘GCONPROD’, ‘WPOLYMER’, ‘WSURFACT’, ‘WELOPEN’ and ‘WELTARG’Be advised that we do not support the complete feature set of these keywords.
See also
-
replaceKeywords(sect, fid, keywords, nc)¶ Replace keywords. Internal function
-
Contents¶ Files initEclipseGrid - Construct MRST grid from ECLIPSE GRID section.
-
initEclipseGrid(deck, varargin)¶ Construct MRST grid from ECLIPSE GRID section.
Synopsis:
G = initEclipseGrid(deck) G = initEclipseGrid(deck, 'pn1', pv1, ...)
Parameters: deck – Raw input data in Deck form as defined by function ‘readEclipseDeck’.
Keyword Arguments: ‘pn’/pv – List of ‘key’/value pairs defining optional parameters. The supported options are:
- mapAxes - Apply the mapAxes transformation if present.
DEFAULT: false.
In addition, the routine can pass on a number of paramters to the function processGRDECL, which is used to construct corner-point grids
Returns: G – Valid ‘grid_structure’
See also
-
Contents¶ Models for three-phase compressible fluids.
- Files
- expandMiscibleTable - Expand Miscible PVT Table Definition to Format Suitable for Visualization
-
expandMiscibleTable(T, varargin)¶ Expand Miscible PVT Table Definition to Format Suitable for Visualization
- SYNOPSIS
- ExTable = expandMiscibleTable(T) ExTable = expandMiscibleTable(T, ‘pn1’, pv1, …)
Parameters: T – - Miscible table, or cell-array of miscible tables, as defined
- by function readEclipseDeck and, possibly, function convertDeckUnits.
- ’pn’/pv - List of ‘key’/value pairs defining optional parameters. The
- supported options are
- inner – Name (string) of inner table range.
- Default: ‘inner’.
- outer – Name (string) of outer table range.
- Default: ‘outer’.
Returns: ExTable – Structure of expanded miscible property table definitions. One element for each input table (typically: PVT region) identified by the argument ‘T’. Example:
% Input simulation deck, convert to MRST's strict SI unit conventions. deck = convertDeckUnits(readEclipsDeck(file)) % Expand PVTO and PVTG Tabulated (Miscible) Property Functions. ExPVTO = expandMiscibleTable(deck.PROPS.PVTO, ... 'inner', 'Po', 'outer', 'Rs') ExPVTG = expandMiscibleTable(deck.PROPS.PVTG, ... 'inner', 'Rv', 'outer', 'Pg') %---------------------------------------------------------------- % Visualize First Region's 'Bo' Factor (i.e., the Oil FVF). [Po, Rs] = deal(convertTo(ExPVTO(1).Po, barsa), ExPVTO(1).Rs); figure surf(Po, Rs, ExPVTO(1).B, ... 'EdgeColor', 'k', 'FaceColor', 'interp', ... 'Marker', '*', 'MarkerEdgeColor', 'r', 'MarkerSize', 5) % Add Contour Plot of 'Bo' for Additional Visual Aid hold on, contour(Po, Rs, ExPVTO(1).B, 101) title('Oil Formation Volume Factor (B_o) [rm^3/Sm^3]') xlabel('Oil Pressure (P_o) [Bar]') ylabel('Dissolved Gas-Oil Ratio (R_s) [Sm^3/Sm^3]') %---------------------------------------------------------------- % Visualize Last Region's Tabulated Gas Viscosity Function [Rv, Pg, mu_g] = deal(ExPVTG(end).Rv, ... convertTo(ExPVTG(end).Pg, barsa), ... convertTo(ExPVTG(end).mu, centi*poise)); figure surf(Pg, Rv, mu_g, ... 'EdgeColor', 'k', 'FaceColor', 'interp', ... 'Marker', '*', 'MarkerEdgeColor', 'r', 'MarkerSize', 5) % Add Contour Plot of 'mu_g' for Additional Visual Aid hold on, contour(Pg, Rv, mu_g, 101) title('Gas Viscosity (\mu_g) [cP]') xlabel('Gas Pressure (P_g) [Bar]') ylabel('Vaporized Oil-Gas Ratio (R_v) [Sm^3/Sm^3]')
See also
readEclipseDeck, convertDeckUnits.
-
Contents¶ Files compressRock - Compress rock properties to active cells only computeTranMult - Compute transmissibility multipliers. initEclipseRock - Extract rock properties from input deck initRelpermScaling - set up the relperm scaling parameters from deck (‘SOGCR’, ‘SGU’, ‘SGCR’, processAquifer - return array aquifer. Each row corresponds to a cell connected to the aquifer.
-
compressRock(rock, active)¶ Compress rock properties to active cells only
Synopsis:
rock = compressRock(rock, active)
Parameters: - rock – Rock data structure formed, e.g., in function ‘initEclipseRock’.
- active – Active cell map. Logical or numeric indices into ‘perm’ (&c) fields that denotes which cell propertis to extract. Often equal to the ‘cells.indexMap’ field of a grid_structure.
See also
-
computeTranMult(G, rockprop)¶ Compute transmissibility multipliers.
Synopsis:
mult = computeTranMult(G, rockprop)
Parameters: - G – Valid grid structure. Must be a logically Cartesian grid such as the grids created by means of functions ‘processGRDECL’ or ‘cartGrid’. Moreover, the half-face tags (G.cells.faces(:,2)) must not contain values outside the set (1 : 6).
- rockprop – Rock property data structure. May contain ECLIPSE multiplier keywords such as ‘MULTX’, ‘MULTY’, or ‘MULTZ-‘ (matched case insensitively). Often corresponds to the ‘deck.GRID’ data structure of function ‘readEclipseDeck’.
Returns: mult – Half-face transmissibility multipliers. An empty array (i.e., mult = []) if the rock property data structure contains no multiplier keyword fields. Otherwise (i.e., when there are multiplier keywords present), a SIZE(G.cells.faces,1)-by-1 DOUBLE array such that ‘mult(i)’ is a transmissibility multiplier for half-face (half-contact) ‘i’.
Note
A multiplier keyword, if present, must contain one datum for each cell in the global grid (PROD(G.cartDims) cells). Values in inactive cells (e.g., due to explicit deactivation or pinch/collapse) are ignored.
We underscore the fact that these multiplier values are designed to go with the half-face (one-sided) transmissibility values derived from function ‘computeTrans’. In particular, the multiplicative factors must be included BEFORE computing the harmonic average of the one-sided transmissibilities.
Example:
%% Compute connection transmissibilities on an ECLIPSE-type model % % 1) Compute background, one-sided transmissibilities htrans = computeTrans(G, rock); % 2) Compute multipliers for one-sided transmissibilities tmult = computeTranMult(G, deck.GRID); if ~ isempty(tmult), % 2b) Include multipliers for one-sided transmissibilities htrans = htrans .* tmult; end % 3) Compute final background (static) transmissibilities trans = 1 ./ accumarray(G.cells.faces(:,1), ... 1 ./ htrans, ... [G.faces.num, 1]);
See also
-
initEclipseDPRock(deck, splitRock)¶ Extract rock properties from input deck
Synopsis:
rock = initEclipseRock(deck)
Parameters: deck – Raw input data in Deck form as defined by function ‘readEclipseDeck’.
Returns: rock – Rock data stucture containing the following fields: - perm – Permeability values. Layout as dictated by function
‘permTensor’.
- poro – Porosity values. Corresponds to ‘PORO’ keyword.
- ntg – Net-to-gross values. Corresponds to ‘NTG’ keyword.
- cr – Rock compressibility. Corresponds to item two of
- ‘ROCK’ keyword (in PROPS section).
- pref – Reference pressure for rock compressibility. Data
- from item one of ‘ROCK’ keyword.
Note
A given ‘rock’ field is only created if the corresponding keyword is present in the input deck.
Example:
%Create a rock data structure for active cells only rock = initEclipseRock(deck) rock = compressRock(rock, G.cells.indexMap)
See also
readEclipseDeck, convertDeckUnits, permTensor, compressRock
-
initEclipseRock(deck)¶ Extract rock properties from input deck
Synopsis:
rock = initEclipseRock(deck)
Parameters: deck – Raw input data in Deck form as defined by function ‘readEclipseDeck’.
Returns: rock – Rock data stucture containing the following fields: - perm – Permeability values. Layout as dictated by function
‘permTensor’.
- poro – Porosity values. Corresponds to ‘PORO’ keyword.
- ntg – Net-to-gross values. Corresponds to ‘NTG’ keyword.
- cr – Rock compressibility. Corresponds to item two of
- ‘ROCK’ keyword (in PROPS section).
- pref – Reference pressure for rock compressibility. Data
- from item one of ‘ROCK’ keyword.
Note
A given ‘rock’ field is only created if the corresponding keyword is present in the input deck.
Example:
%Create a rock data structure for active cells only rock = initEclipseRock(deck) rock = compressRock(rock, G.cells.indexMap)
See also
-
initRelpermScaling(deck, nc)¶ set up the relperm scaling parameters from deck (‘SOGCR’, ‘SGU’, ‘SGCR’, ‘SWCR’, ‘SOWCR’, ‘KRW’, ….) Note: non-active cells are also assigned a value.
-
processAquifer(deck, G)¶ return array aquifer. Each row corresponds to a cell connected to the aquifer. the aquind structure gives the content of each column:
-
Contents¶ - WELLS_AND_BC
- Support for Constructing Wells and Boundary Conditions From Input Decks
- Files
- processWells - Construct MRST well structure from ECLIPSE input deck control.
-
processWells(G, rock, control, varargin)¶ Construct MRST well structure from ECLIPSE input deck control.
Synopsis:
W = processWells(G, rock, control) W = processWells(G, rock, control, 'pn1', pv1, ...)
Parameters: - G – Grid data structure.
- rock – Rock data structure. Must contain valid field ‘perm’.
- control – Well control mode. Assumed to be defined from function ‘readSCHEDULE’.
- 'pn'/pv –
- List of ‘key’/value pairs defining optional parameters. The
- supported options are:
- InnerProduct – The inner product with which to define
- the mass matrix. String. Default value = ‘ip_tpf’.
- Supported values are:
- ’ip_simple’
- ’ip_tpf’
- ’ip_quasitpf’
- ’ip_rt’
- Verbose – Whether or not to emit informational messages
- if any requested well control mode is unsupported. Logical. Default value = false.
- DepthReorder – Boolean indicating if we should attempt to
- reorder the perforations by depth. Should only be used for vertical wells. Default off.
- strictParsing – Throw errors if unsupported well controls
- are encountered. If disabled, wells with unsupported controls will recieve NaN values for control and phase composition.
- createDefaultWell – If enabled, this function will not parse
- any wells, but simply return a default well structure suitable for further modification.
- cellDims – optional input of accurate cellDims
Returns: W –
- Updated (or freshly created) well structure, each element of which
has the following fields: cells – Grid cells perforated by this well. type – Well control type. val – Target control value. r – Well bore radius. dir – Well direction. WI – Well index. dZ – Vertical displacement of each well perforation measured
from ‘highest’ horizontal contact (i.e., the ‘TOP’ contact with the minimum ‘Z’ value counted amongst all cells perforated by this well).
name – Well name. compi – Fluid composition–only used for injectors. sign – injection (+) or production (-) flag. status – Boolean indicating if the well is open or shut. cstatus – One entry per cell, indicating if the completion is
open.
- lims – Limits for the well. Contains subfields for the types
of limits applicable to the well (bhp, rate, orat, …) Injectors generally have upper limits, while producers have lower limits.
c – Component concentrations. Unit convention may vary.
See also
-
processWellsDP(G, rock_matrix, rock_fracture, control, varargin)¶ Construct MRST well structure from ECLIPSE input deck control.
Synopsis:
W = processWells(G, rock, control) W = processWells(G, rock, control, 'pn1', pv1, ...)
Parameters: - G – Grid data structure.
- rock – Rock data structure. Must contain valid field ‘perm’.
- control – Well control mode. Assumed to be defined from function ‘readSCHEDULE’.
- 'pn'/pv –
- List of ‘key’/value pairs defining optional parameters. The
- supported options are:
- InnerProduct – The inner product with which to define
- the mass matrix. String. Default value = ‘ip_tpf’.
- Supported values are:
- ’ip_simple’
- ’ip_tpf’
- ’ip_quasitpf’
- ’ip_rt’
- Verbose – Whether or not to emit informational messages
- if any requested well control mode is unsupported. Logical. Default value = false.
- DepthReorder – Boolean indicating if we should attempt to
- reorder the perforations by depth. Should only be used for vertical wells. Default off.
- strictParsing – Throw errors if unsupported well controls
- are encountered. If disabled, wells with unsupported controls will recieve NaN values for control and phase composition.
- createDefaultWell – If enabled, this function will not parse
- any wells, but simply return a default well structure suitable for further modification.
- … automodule:: deckformat.resultinput
members:
Simulator¶
-
initEclipseModelDP(inputfile, varargin)¶ Initialise basic MRST objects from ECLIPSE input file (*.DATA)
Synopsis:
[G, rock_fracture, rock_matrix, fluid_matrix, fluid_fracture, state, wells, ... htransf, transf, htransm, transm, dt, deck, DP_info] = initEclipseModelDP(inputfile,'pn1','pv1',..)
Description:
Function ‘initEclipseModelDP’ constructs the fundamental MRST simulation objects (grid, rock properties, fluids &c) from a single ECLIPSE-style input file (typically named ‘*.DATA’). This reader has been modifed to read in and setup dual porosity/permeability models.
- PARAMS:
- inputfile - Name (string) of input file. The input is assumed to be a
- regular file on disk and not, say, a POSIX pipe.
Keyword Arguments: ‘pn’/pv – List of ‘key’/value pairs defining optional parameters. These are passed on to the function ‘processGRDECL’, which is used to construct corner-point grids. Of particular interest is the parameter ‘SplitDisconnected’ which tells whether or not to split disconnected grid components into separate grids/reservoirs.
Returns: - G – Grid structure as defined by function ‘initEclipseGrid’.
- rock_fracture – Fracture Rock data structure as defined by function ‘initEclipseRockDP’.
- rock_matrix – Matrix Rock data structure as defined by function ‘initEclipseRockDP’.
- fluid_matrix – Matrix Fluid data structure as defined by function ‘initEclipseFluid’.
- fluid_fracture – Fracture Fluid data structure as defined by function ‘initEclipseFluid’.
- wells – Initial well object as defined by function ‘processWells’. This structure is derived from the initial well configuration.
- htrans – Background (absolute) one-sided transmissibilities as defined by functions ‘computeTrans’ and ‘computeTranMult’. Also incorporates net-to-gross factors if available.
- trans – Background (absolute) connection transmissibilities defined by harmonic averaging of the one-sided transmissibilities (htrans) while including fault-related transmissibility multipliers too.
- dt – Report step sequence derived from ‘TSTEP’ and ‘DATES’.
- deck – Raw input deck as defined by functions ‘readEclipseDeck’ and ‘convertDeckUnits’. Especially usefull for the dynamic SCHEDULE information pertaining to switching well controls.
- DP_info – Dual porsity information sigma, matrix block sizes
- NOT Handled for DP models Yet
- state – Initial state object as defined by function ‘initEclipseState’.
Examples¶
Read/convert ECLIPSE output and visualize using interactive diagnostics¶
Generated from diagnosticsFromEclipseOutput.m
This example reads ECLIPSE unformatted output files from a simulation based on the SPE-9 benchmark. The data is converted to MRST grid and soluion structures and used as input to the interactive diagnostics functionality.
mrstModule add mrst-gui ad-core diagnostics
if ~ makeSPE9OutputAvailable
error('SPE9Download:Failure', ...
'Failed to download ECLIPSE output for SPE-9 benchmark case');
end
prefix = fullfile(getDatasetPath('spe9'), 'Simulation-Output', 'SPE9_CP');
Read INIT/EGRID-files and construct MRST-grid¶
init = readEclipseOutputFileUnFmt([prefix, '.INIT']);
egrid = readEclipseOutputFileUnFmt([prefix, '.EGRID']);
[G, rock] = eclOut2mrst(init, egrid);
G = computeGeometry(G);
Read restart step 10 and convert to mrst-state¶
step = 10;
states = convertRestartToStates(prefix, G, 'steps', 10);
state = states{1};
Set up a compatible well structure (W)¶
The wellSol-field of state contains sufficient data to work as a well-struct (W).
W = state.wellSol;
If flux field is not given in ECLIPSE restart (as here), the converted state will not contain fluxes either. In this case, interactiveDiagnostics will need to solve an incompressible pressure equation in order to reconstruct a reasonable flux field. We therefore need to adjust W such that its control settings are compatible with the incompressible solvers. Here we set W(1) (the injector) to be controlled by bottom-hole pressure target (BHP), and W(2:end) (the producers) to be controlled by rate. We set the rate values to the reservoir volume rates computed by ECLIPSE (resv).
[W(1).type, W(1).val] = deal('bhp', W(1).bhp);
for wnum = 2:numel(W)
[W(wnum).type, W(wnum).val] = deal('rate', W(wnum).resv);
end
Run Interactive diagnostics¶
close all, interactiveDiagnostics(G, rock, W, 'state', state);
figure(1), daspect([1, 1, 0.3]), view([1, -0.5, 1])
New state encountered, computing diagnostics...
Warning: Inconsistent Number of Phases. Using 1 Phase (=min([3, 1, 1])).
Read ECLIPSE output and convert to MRST grid and solution structures¶
Generated from readAndConvertEclipseOutput.m
This example reads ECLIPSE unformatted output files from a simulation based on the SPE-9 benchmark. The MRST grid structure (G) is generated using output from *.INIT and *.EGRID. The solution structure (states and states{i}.wellSol) are generated using output from *.UNRST.
mrstModule add mrst-gui ad-core
if ~ makeSPE9OutputAvailable
error('SPE9Download:Failure', ...
'Failed to download ECLIPSE output for SPE-9 benchmark case');
end
prefix = fullfile(getDatasetPath('spe9'), 'Simulation-Output', 'SPE9_CP');
Read INIT/EGRID-files and generate MRST-grid¶
init = readEclipseOutputFileUnFmt([prefix, '.INIT']);
egrid = readEclipseOutputFileUnFmt([prefix, '.EGRID']);
[G, rock] = eclOut2mrst(init, egrid);
G = computeGeometry(G);
Restart-to-states converter reads selected parts of UNRST-file.¶
Each state (states{i}) contains a ‘wellSol’ structure containing sufficient welldata for plotting (e.g., perforation cells).
states = convertRestartToStates(prefix, G);
% Fetch wellsols and restart-step times
wellSols = cellfun(@(x)x.wellSol, states, 'UniformOutput', false);
time = cellfun(@(x)x.time, states);
Plot model with wells¶
figure, plotToolbar(G, states);
plotWellData(G, wellSols{1}, 'labelFontSize', 10, ...
'color', [0.3, 0.3, 0.3]);
axis off vis3d tight, view([1, -0.5, 1]), camproj perspective
Read ECLIPSE output and visualize¶
Generated from readAndVisualizeEclipseOutput.m
This example reads ECLIPSE unformatted output files from a simulation based on the SPE9 benchmark. The MRST grid structure (G) is generated using output from *.INIT and *.EGRID. Unconverted grid properties from *INIT and *UNRST (restart data) are plotted using plotToolBar. Summary data (*UNSMRY) is read and inspected.
mrstModule add mrst-gui
if ~ makeSPE9OutputAvailable
error('SPE9Download:Failure', ...
'Failed to download ECLIPSE output for SPE-9 benchmark case');
end
prefix = fullfile(getDatasetPath('spe9'), 'Simulation-Output', 'SPE9_CP');
Read INIT/EGRID-files and construct MRST-grid¶
init = readEclipseOutputFileUnFmt([prefix, '.INIT']);
egrid = readEclipseOutputFileUnFmt([prefix, '.EGRID']);
[G, rock] = eclOut2mrst(init, egrid);
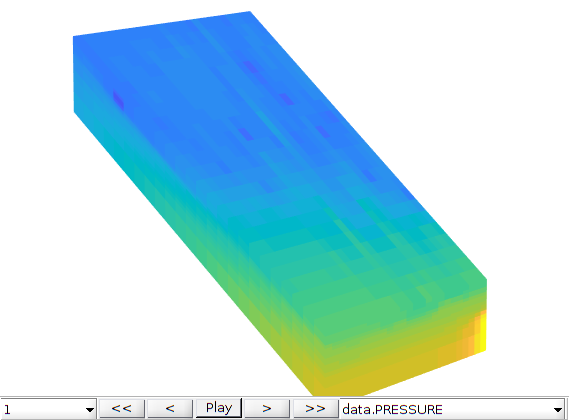
Plot (unconverted) init data compatible with the grid (G)¶
figure, plotToolbar(G, init);
axis off vis3d tight, view([1 -1.5 .3]), camproj perspective

Read and plot (unconverted) restart data compatible with the grid (G)¶
By first reading the restart specification file, we may choose to read only portions of the restart data. Here er read all data for for time-steps 1 through 20.
spec = processEclipseRestartSpec(prefix, 'all');
steps = 1:20;
rstrt = readEclipseRestartUnFmt(prefix, spec, steps);
The data-arrangement in rstrt is not compatible with plotToolbar, hence we need to rearrage the data as a struct-array. At the same time we only pick data that matches the number of grid cells.
ix = structfun(@(x)numel(x{1}) == G.cells.num, rstrt);
f = fieldnames(rstrt); f = f(ix);
Rearrange restart-data to array of structures for plotting
data = cellfun(@(x)rstrt.(x), f, 'UniformOutput', false);
data = cell2struct(vertcat(data{:}), f, 1);
Plot selected restart data
figure, plotToolbar(G, data);
axis off vis3d tight, view([1, -1.5, 0.3]), camproj perspective
Read and inspect (unconverted) summary data¶
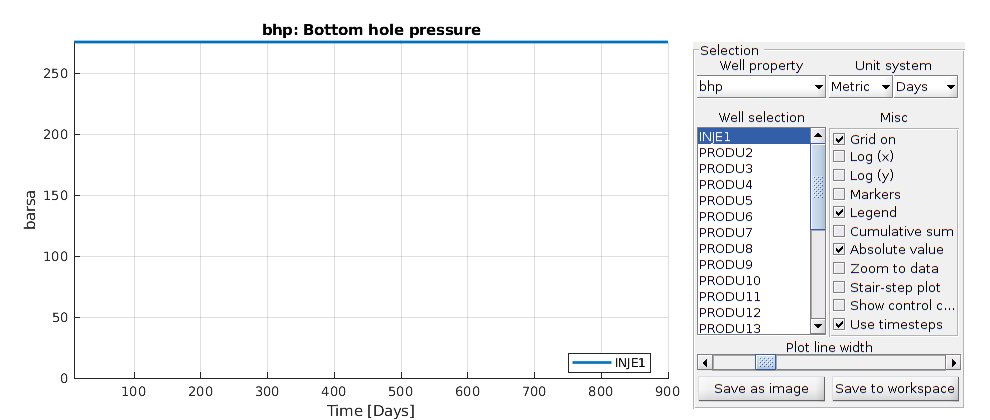
The summary reader creates a struct smry containg all the data in an array accompanied by index-functions for extracting data for a given well/property/timestep. The reader requires both the *.UNSMRY and *.SMSPEC files.
smry = readEclipseSummaryUnFmt(prefix);
Display names of all “wells” for which properties are recorded:
smry.WGNAMES
ans =
28×1 cell array
{':+:+:+:+'}
{'FIELD' }
{'INJE1' }
...
The field with the expressive name ‘:+:+:+:+’ contains ministep (simulator time-step) times given by the property ‘TIME’. Request times of all (‘:’) ministeps:
time = smry.get(':+:+:+:+', 'TIME', ':');
% Find property names ascossiated with the field 'FIELD'
smry.getKws('FIELD')
ans =
4×1 cell array
{'FGOR'}
{'FGPR'}
{'FOPR'}
...
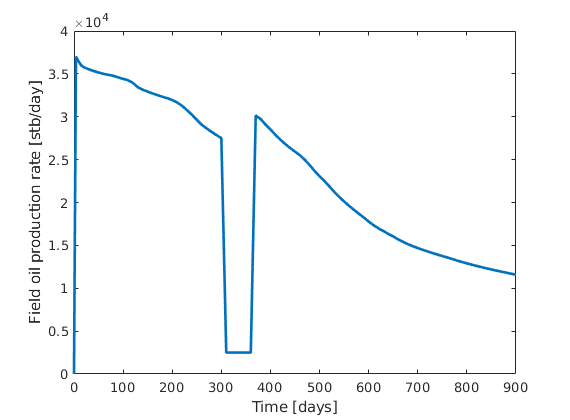
Plot field oil production rate for all time steps
figure, plot(time, smry.get('FIELD', 'FOPR', ':'), 'LineWidth', 2);
xlabel('Time [days]'), ylabel('Field oil production rate [stb/day]');