
Safe and Sustainable Development of an AI Chatbot for German Primary Care
This project focuses on responsible integration of artificial intelligence (AI) into general practice in Germany, specifically through co-development of an AI-powered chatbot.
This project focuses on responsible integration of artificial intelligence (AI) into general practice in Germany, specifically through co-development of an AI-powered chatbot.

Detect and mitigate climate change risk damage for optimal property value preservation

INDEE3 supports sustainable cooling and heating in India by promoting natural refrigerants, reducing emissions, and boosting cold chain efficiency in food, seafood, and building sectors.

The project conducts follow-up research on the “Usability Program,” which aims to improve the usability of the Helseplattformen system. Insights from the research will help the Program achieve its goals. Increased usability leads to greater...

Our aim is to develop a next-generation diagnostic device that can detect carbapenemase-producing bacteria directly from patient samples - such as blood, urine, or swabs - in under 15 minutes, without the need for time-consuming lab cultures.

QSENS aims to improve upon Superconducting Nanowire Single-Photon Detector quantum sensors (SNSPDs). SNSPDs can be utilized as stand-alone sensors or a components in quantum computers or quantum communication.

SeaWeave aims to pioneer new knowledge and technologies for a blue biorefinery model, focusing on converting red and brown seaweed into innovative and sustainable fibers and dyes, contributing to increased valorization of underutilized renewable...

- Improving energy production and safety in biocarbon value chains

Optimizing Yard Operations (OYO) will provide innovative technology that incorporates optimization algorithms for planning resource-efficient stabling and shunting in train yards.
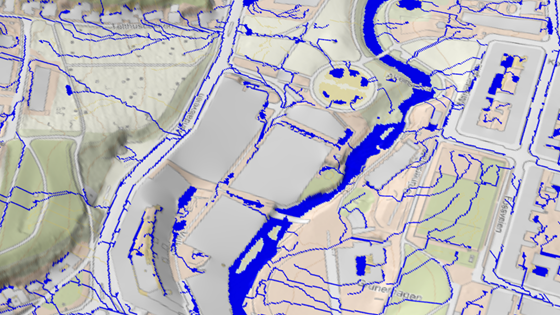
Reducing societal risk in a changing climate using nature-based solutions in sustainable urban area development
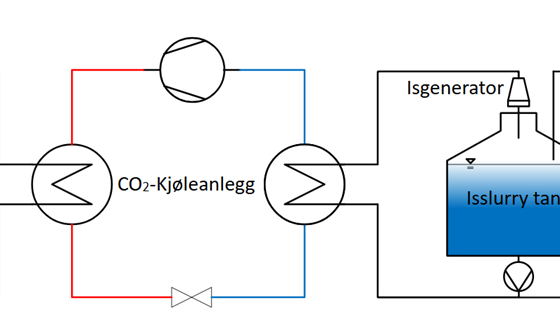
Development of an energy efficient method for thermal energy storage using ice slurry in dairies, with a focus on reducing peak loads, optimising energy use and ensuring high product quality.

Scalable, Plug & Play and Modular DC Power Systems for low-emission Large Vessels

Efficient HV-electric modular battery and distribution systems for sustainable WAterborne VEssels

The project will develop new knowledge and propose measures to reduce the risk for personnel in the aquaculture industry. A particular focus is safety challenges that arise at the interface between different organisations.

The project aims to change the way buildings manage energy consumption through innovative sensor-based control of ventilation systems.

Healthcare researchers at SINTEF will conduct a research project for the Program for Urban Research (KS), with Stavanger Municipality as the project owner. The purpose of the project is to shed light on the challenges in mental health and substance...
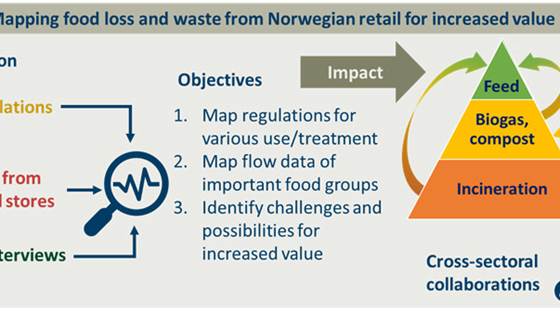
In this pilot project, food waste in Norwegian grocery stores will be mapped to highlight effective measures and assess opportunities for increasing the use of biogas and combustion for feed.

The goal of RACE Autofôring is to develop and test AI-based feeding strategies that improve feed efficiency, growth, and welfare in salmon farming.